Cet article fait suite à la première partie : Introduction & Rappels des RAG
Performance et scalabilité des systèmes RAG
Passer de deux ou trois utilisateurs avec peu de documents et des temps de réponse rapides à la gestion de plusieurs milliers d'utilisateurs avec plusieurs centaines de milliers de documents (milliards de segments ou d'informations atomiques)
et des temps de réponse de l'ordre de la seconde est un véritable défi, et vous devrez résoudre de nombreux problèmes de performance.
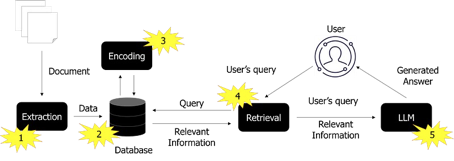
Processus RAG (source : auteur)
Les approches RAG sont confrontées à plusieurs problèmes de performance :
- Extraction : L'extraction de documents est un problème difficile lorsqu'elle concerne plusieurs millions d'unités, avec de grands corpus de textes. On se retrouve rapidement à gérer des milliards de segments
et des temps d'ingestion de l'ordre d'une semaine ou d'un mois. Selon l'approche adoptée, la mise à jour de l'information devient également un défi en termes de complexité, surtout si l'on a opté pour
une approche par graphe de connaissances. Plus on a de documents, plus on risque de devoir gérer plusieurs langues différentes, et donc le problème de la gestion de l'information et de la recherche : une requête en français
doit-elle aussi renvoyer des documents en anglais ?
- Base de données : Dans le cas d'une documentation importante, la base de données doit avant tout gérer un grand volume d'informations. Dans le cas d'une base de données vectorielle, un temps de réponse
de 0,2 ms pour un calcul de similarité n'est pas significatif avec mille valeurs mais devient prohibitif si vous avez un million de valeurs à comparer. Vous obtiendrez votre réponse après plus de 3 minutes si vous gérez
cela de manière séquentielle. Deuxièmement, la base de données sera sollicitée très souvent si vous avez plusieurs milliers d'utilisateurs simultanés. La mise en cache, la redondance et le temps
de réponse sont alors de nouveaux problèmes à gérer. Si vous avez décidé de sauvegarder tous les segments dans la base de données, n'oubliez pas que vous allez dupliquer vos corpus de texte. Les
fournisseurs de bases de données vectorielles ont un modèle économique lié à l'empreinte mémoire : plus vous avez de vecteurs, plus vous devrez payer !
- Encodage : Au niveau de l'encodage, l'utilisation d'un modèle pré-entraîné est aujourd'hui très facile. L'activité non triviale consiste à sélectionner le bon modèle. Vous
devez mélanger ces contraintes : la taille de l'entrée (longueur maximale du segment) et de la sortie (taille de l'espace latent), la latence pour générer le vecteur, le(s) langage(s), le vocabulaire métier,
la mémoire utilisée, la licence, la performance de similarité, directe ou reranker... Lorsque vous utilisez des graphes, l'intégration de vecteurs de graphes peut être une bonne approche pour calculer la similarité,
mais la liste de ces techniques est vaste et sort de la portée de cet article. Si vous gérez des images dans le cas du MMRAG, l'encodage peut être un défi puisque ces techniques sont relativement nouvelles.
- Récupération : Le module de recherche a la tâche délicate d'analyser les demandes des utilisateurs. Il doit donc faire face à un volume potentiellement important de demandes. Il est responsable du
contrôle de la recherche et de la génération, et contrôle donc la génération de la réponse à l'aide d'un ou de plusieurs modèles linguistiques. L'un des défis consiste également
à gérer les droits de l'utilisateur jusqu'au document ou à l'élément de document auquel il est autorisé à accéder. Les droits doivent être gérés tout au long du processus,
de l'ingestion à la génération. Dans le processus de réécriture des requêtes, la nécessité d'un LM pourrait retarder le temps de traitement global. Si vous incluez une approche multi-sauts,
l'accélération du temps de réponse global devient alors un véritable défi. Si vous augmentez le nombre de capacités de recherche comme la similarité avec BM25, et la recherche dans un graphe, être
capable de trier les différents résultats est également un défi où le RRF (Reciprocal Rank Fusion)
pourrait être appliqué pour résoudre ce problème.
- LLM (Générer) : C'est à la fois la partie techniquement la plus facile lorsqu'elle est gérée par un fournisseur d’API dans le Cloud et la plus complexe lorsqu'il s'agit d'avoir le modèle
à la maison. C'est également la partie la moins respectueuse de l'environnement, car les grands modèles nécessitent une infrastructure importante, surtout s'ils doivent prendre en charge un très grand nombre
d'inférences. Les techniques de vérification des résultats utilisant des modèles de langage améliorent les résultats, mais augmentent également les exigences, et donc les coûts et les temps
de latence.
Les techniques utilisées pour améliorer la précision globale du système, que ce soit en amont, en aval ou entre les deux, peuvent faire une réelle différence, mais entraînent des retards et des charges de
travail supplémentaires qui peuvent avoir un effet préjudiciable sur la latence finale et donc sur l'expérience de l'utilisateur. Le choix de répondre rapidement ou correctement est une décision qui peut peser lourdement
sur l'architecture. Il est difficile d'optimiser simultanément pour ne renvoyer que les résultats pertinents (précision) et ne manquer aucun résultat pertinent (rappel).
Prompt engineering et complexité des entrées
Prompt Engineering
Vous avez peut-être remarqué l'apparition sur le marché d'un nouveau métier appelé "Prompt Engineer". Il s'agit pour cet ingénieur de travailler sur les messages-guides (le texte utilisé en entrée
des grands modèles de langage, appelé prompt en anglais) afin d'obtenir le meilleur résultat possible, en fonction du LM utilisé. La préparation de la meilleure invite en fonction de l'intention de l'utilisateur
est la deuxième partie la plus importante après la recherche.
Vous avez peut-être déjà constaté qu'il suffit parfois d'ajouter un simple retour chariot ou "###" à l'invite pour modifier la réponse et obtenir un meilleur résultat. La plupart des bibliothèques
ont intégré le formatage de l'invite, en conservant la question posée et en l'entourant d'un texte supplémentaire. L'expérience montre que de nombreuses itérations sont nécessaires pour obtenir la meilleure
invite.
Une partie complexe du travail du prompteur consiste à gérer tout ce qui sort du cadre de la manière la plus naturelle possible. Les réseaux génératifs sont formés pour générer des jetons
à partir de données d'entrée. Il leur est donc difficile de ne pas répondre à la demande de l'utilisateur. C'est particulièrement vrai lorsqu'on adopte une approche de type "livre fermé". C'est encore
le cas dans l'approche RAG, avec l'avantage que les questions hors du champ d'application pourraient être gérées en amont, pendant la tâche de recherche, et en aval de la génération.
Nous attendons que les LM ayant une approche à livre fermé soient capables d'effectuer de nombreuses tâches métiers, telles que répondre à une question, générer des idées ou résumer
un document. Il est alors nécessaire de fournir de bonnes informations et de rédiger un bon message puisque les données que nous devons présenter au modèle peuvent être différentes. Cela signifie que
nous devons évoluer vers un système multitâche et ne pas nous contenter de fournir les données et les questions. Et nous savons tous que les questions peuvent être complexes et doivent être adaptées au
contexte.
Les LM à contexte long modifient la conception des RAG puisqu'ils permettent de définir des documents complets. Toutefois, il est difficile de répondre à des questions de niveau inférieur à partir d'un seul document
ou à des questions de niveau supérieur qui s'étendent sur plusieurs documents.
Complexité des entrées
Lorsque nous parlions de complexité des entrées dans le précédent article, nous évoquions la difficulté à prendre en compte les formats des sources de documents, la complexité des images et les requêtes
de l'utilisateur.
La plupart des formats de documents sont "faciles" à gérer, tels que les documents texte et les documents Microsoft Office, mais pas les PDF (le format le plus laid au monde de mon point de vue, avec le CSV en deuxième position).
Le PDF étant un format d'affichage, l'extraction de données est un défi : les textes peuvent être placés n'importe où sur la page ; les documents scientifiques contiennent des textes en plusieurs colonnes,
des tableaux complexes, des schémas, des figures, des formules, des en-têtes/pieds de page et des notes de bas de page (et ils contiennent parfois des informations très importantes) ; les titres des chapitres ne sont pas toujours
numérotés car l'auteur peut avoir joué avec la taille de la police ; les pages peuvent avoir été scannées... Cependant, le défi d'extraire tous les éléments d'un PDF est de plus en plus
facile à relever, car il existe de nombreux nouveaux modèles capables de comprendre le format d'une page d'un point de vue visuel, et de nombreux outils d'OCR pour extraire le texte, les tableaux et les formules.
Lorsque nous traitons des images, nous devons prendre en compte une grande variété de cas possibles, tels que des schémas d'assemblage, des histogrammes, des graphiques, des photos commentées, etc. En fait, il peut y avoir
une énorme quantité d'informations difficiles à traiter et à gérer, comme vous l'avez peut-être expérimenté lors du montage de certains meubles. Ces informations sont souvent oubliées et
ne contribuent pas à l'effort de réponse.
Enfin, la partie la plus complexe est tout simplement celle des utilisateurs et de leur capacité à poser des questions complexes. Vous trouverez ci-après un tableau reprenant tous les modèles RAG et les cas d'utilisation correspondants.
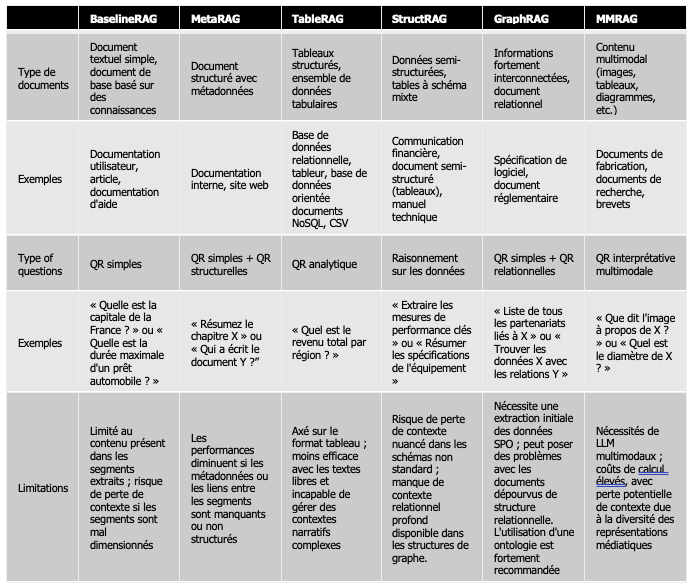
Ce tableau doit vous permettre de déterminer quel RAG vous devez mettre en place en fonction des questions posés par vos utilisateurs mais également en fonction du format des données en entrée.
Approche du flux de travail par l'intelligence artificielle (approche StarRAG ou MultiRAG)
Nous définissons un système d'IA multi-agent comme un système qui aborde les tâches en utilisant l'interaction entre plusieurs agents augmentés à l'aide d'un modèle de langage. Au lieu de laisser un LM générer
sa sortie finale directement à partir d'une invite (modèle statique), un flux de travail d'agent interroge le(s) LM plusieurs fois, lui donnant la possibilité de construire une sortie de meilleure qualité étape par
étape. En dotant un agent d'outils, il est possible de lui donner les compétences nécessaires pour effectuer des actions spécifiques telles que la recherche d'un fichier sur le réseau, le résumé d'un
document, l'extraction d'informations à partir d'un document.
Dans l'approche *RAG, le système multi-agent est utilisé avec un planificateur qui décompose la question de l'utilisateur en une séquence d'étapes et achemine les demandes vers un ou plusieurs agents RAG spécialisés
dans le type de données concerné et en fonction du type de question. Un agent est chargé de rassembler les différents résultats pour produire la réponse finale.
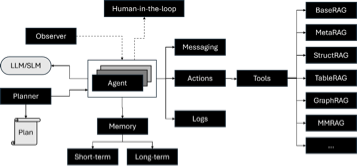
Organisation du flux de travail agentique *RAG (source : auteur)
Sécurité, vie privée, préjugés et autres considérations
L'ensemble du système doit résister aux attaques manipulatrices qui pourraient conduire à une compromission : injection d'invites, génération de contenu nuisible, gestion hors domaine.
Dans le domaine de la sécurité, plusieurs items doivent être couvertes par la solution :
- Authentification des utilisateurs : Garantir des mécanismes d'authentification solides pour empêcher tout accès non autorisé au niveau de l'application, mais aussi au niveau des données.
- Chiffrement des données : Cryptage des données au dépôt et en transit pour les protéger contre l'interception ou les violations. Au fur et à mesure que les documents sont traités,
les données sont distribuées aux différentes bases de données où l'information est finalement lisible et extraite de sa forteresse initiale.
- Audits réguliers : Réaliser des audits de sécurité et des évaluations de vulnérabilité pour identifier et atténuer les menaces potentielles.
- Validation des entrées : Mise en œuvre d'une validation approfondie des entrées afin de prévenir les attaques par injection et de garantir que seules des données sûres sont traitées.

Liste des menaces pour la sécurité (source : auteur)
Comme le décrit l'article "A Survey on Hallucination in Large Language Models : Principles, Taxonomy, Challenges, and Open Questions" par Lei Huang, Weijiang Yu et al, il
est fort possible que la génération ne produise pas ce qui est attendu. Des outils comme Guardrails peuvent aider à assainir les entrées et les sorties
en fonction d'un ensemble de risques. Guardrails exécute des gardes d'entrée/sortie dans l'application qui détectent, quantifient et atténuent la présence de types spécifiques de risques et plusieurs
validateurs peuvent être combinés.
Conclusion et perspectives
Une étude réalisée au début de l'année par Gartner a montré qu'en moyenne, seuls 48 % des projets d'IA aboutissent à une production, et qu'il faut huit mois pour passer
du prototype d'IA à la production.
Le passage du prototype à la production est donc un véritable problème pour les équipes informatiques. Produire rapidement un BaselineRAG à l'aide de frameworks open-source est facile mais il est donc important de
se poser les bonnes questions fonctionnelles et techniques dès le début du projet pour être certain de délivrer finalement ce qui est réellement attendu sur le plan fonctionnel et avec les meilleures performances
en fonction des contraintes opérationnelles.
Pouvoir répondre à de nombreuses typologies de questions est un problème qui va se présenter de plus en plus couramment au fur et à mesure de l’adoption de ces systèmes. Pour cela, les systèmes
multi-agents ajoutent cette nouvelle façon de concevoir les chaînes de traitement et ainsi pouvoir répondre à une demande en fonction des données à traiter.
Cependant, ces architectures sont relativement instables pour le moment, la recherche de nouvelles façons de répondre à toutes les questions des utilisateurs n'est donc pas terminée.